ToC
オペレーション上の障害でログ調査が必要になり、Athenaを使い始めました。
Athenaを使うとS3上のログファイルに対してブラウザ上でクエリをちょこちょこと書いて検索するだけなので非常に便利です。ただ、現実には毎日や毎時ごとのパーティションを事前に作成する必要があり、この作業が結構忘れがち、、なので「Lambdaからパーティション作成をやってしまおう」という算段です。
定期的にLambdaからAthenaを実行する
Athenaを利用してクエリを実行するためには、「マネージメントコンソールの利用」か「JDBC接続」の方法しか提供されていません (2017/5/1現在)。 LambdaならJavaという選択肢もあるのですが、今回はPythonからJDBCラッパー(jaydebeeapi)を利用してみました。

まずは、Athenaのテーブルを作成
Lambdaの話の前にQueryを実行する対象となるAthena側の環境を整えましょう。 Athenaのベストプラクティスとして、Apache Hive方式のデータパーティションの形式にS3にファイルを格納しておくというパターンがあります。今回はこの形式でログファイルを配置しました。
ここでは、Athenaの提供サンプルを例として利用します。
テーブルのRootディレクトリの中に year=2015 month=01 day=01 とkey=valueの形式でパーティション用のサブディレクトリを作成して、その中にファイルが配置されています。
# S3上のKey構造
$ aws s3 ls s3://athena-examples-[aws.region]/elb/orc/year=2015/month=01/
PRE day=01/
PRE day=02/
PRE day=03/
PRE day=04/
PRE day=05/
PRE day=06/
PRE day=07/
# 配置するログファイル
$ aws s3 ls s3://athena-examples-[aws.region]/elb/orc/year=2015/month=01/day=01/
2017-02-16 00:26:24 6806990 part-r-00151-45043f09-35a3-4db2-bfdd-fe182520ee6a.zlib.orc
あとは、こんな感じでAthenaでテーブルを作成します。 パーティションのキーを作成した以外は、ほぼAthenaのBluePrintのままです。
CREATE EXTERNAL TABLE IF NOT EXISTS elb_logs_orc (
request_timestamp string,
elb_name string,
request_ip string,
request_port int,
backend_ip string,
backend_port int,
request_processing_time double,
backend_processing_time double,
client_response_time double,
elb_response_code string,
backend_response_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
url string,
protocol string,
user_agent string,
ssl_cipher string,
ssl_protocol string )
PARTITIONED BY(
year int,
month int,
day int
)
STORED AS ORC
LOCATION 's3://athena-examples-[aws.region]/elb/orc/'
tblproperties ("orc.compress"="ZLIB")
次にパーティションの作成
key=valueの形式でディレクトリが存在していて、テーブル作成時にパーティションのキー指定されていれば、パーティションの作成は非常に簡単です。 Athenaにて下記クエリーを実行すると、新しいS3のディレクトリがあるかを確認して新しいディレクトリが作成されている場合にはAthenaのテーブルのパーティションとして追加します。 今回作成するLambdaにて、定期実行させたいクエリーはこのREPAIR TABLEのクエリーです。
MSCK REPAIR TABLE elb_logs_orc
本題のLambda Functionの作成
いよいよ本題のLambda Functionの作成です。 最終的なディレクトリ構成は、大きく分けると4つの分類で構成されます。
1: jaydebeapiクラス
jaydebeapiクラスについては、下記のサイトが詳しいです。 紹介されているプリペアドステートメント修正版のファイルをそのままで利用できました。 PythonでAmazon Athenaにつなぐ
2: jpype Pythonパッケージ と _jpype.soライブラリ
jaydebeapiクラスで使用されている内部ライブラリです。
Lambdaの標準ライブラリに含まれていないためLambda Funcrionとして動作させる際には、ZIPパッケージの中にバンドルする必要があります。
MacでLocalインストールされたファイルをそのまま使おうとすると「invalid ELF header」というエラーに見舞われますので、EC2上のAmazon Linuxで pip install した際のファイルを利用することがおすすめです。
$ sudo yum install gcc*
$ sudo pip install Jpype1
$ cd /usr/local/lib64/python2.7/site-packages/
$ ls -al
drwxr-xr-x 3 root root 4096 May 3 03:31 jpype #---- [2-1]
drwxr-xr-x 2 root root 4096 May 3 03:31 JPype1-0.6.2.egg-info
-rwxr-xr-x 1 root root 7722158 May 3 03:31 _jpype.so #---- [2-2]
drwxr-xr-x 3 root root 4096 May 3 03:31 jpypex
-rw-r--r-- 1 root root 119 Sep 1 2016 README
3: AthenaJDBC Jarファイル
AthenaJDBCはAWSのドキュメントにリンクがありますので、ダウンロードして完了です。 Accessing Amazon Athena with JDBC
4: Lambda Function
Lambda Funtionは下記のような形で作成しました。 本当はCredential設定をLambdaの実行Roleのものを使ってJDBCアクセスを実行したかったのですが、実行時にUnrecognizedClientExceptionのエラーが出てしまいました。 そのため、現状はIAM UserのCredentialで実行しています。今後の改善課題です。
# -*- coding: utf-8 -*-
from __future__ import print_function
from __future__ import unicode_literals
import jaydebeapi
REGION = '[aws.region]'
CONNECTION_STRING = 'jdbc:awsathena://athena.{region}.amazonaws.com:443/'.format(region=REGION)
DRIVER_CLASS_NAME = 'com.amazonaws.athena.jdbc.AthenaDriver'
JAR_PATH = 'AthenaJDBC41-1.0.1.jar'
AWS_ACCESS_KEY = 'YOUR_ACCESS_KEY_HERE'
AWS_SECRET_ACCESS_KEY = 'YOUR_SECRET_ACCESS_KEY_HERE'
S3_STAGING_DIR = 's3://aws-athena-query-results-[aws.account.id]-[aws.region]/result/'
def lambda_handler(event, context):
main(JAR_PATH)
return True
def main(jarpath, user=None, password=None, s3_stag_dir=None):
if user is None:
user = AWS_ACCESS_KEY
if password is None:
password = AWS_SECRET_ACCESS_KEY
if s3_stag_dir is None:
s3_stag_dir = S3_STAGING_DIR
driver_args = []
driver_args.append(CONNECTION_STRING)
driver_args.append({
'user': user,
'password': password,
's3_staging_dir': s3_stag_dir
})
conn = jaydebeapi.connect(DRIVER_CLASS_NAME, driver_args, jarpath,)
curs = conn.cursor()
exec = curs.execute("MSCK REPAIR TABLE elb_logs_orc")
curs.close()
conn.close()
return
デプロイ
Lambda Functionのデプロイ用のZipファイルを作成して、デプロイします。 実行時間が3秒だとタイムアウトしてしまうので、少し長めに設定する必要があります。 最後に作成したCloudWatchEvent機能で日次実行するようにすれば、ログが出力されれば定期的にAthenaテーブルのパーティションを再作成してくれます。
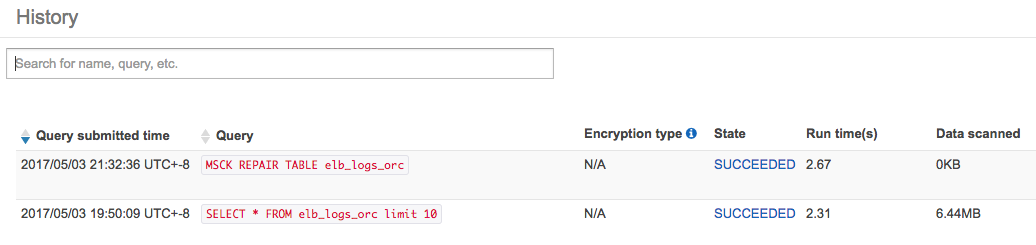
AthenaのHistoryにもちゃんと実行結果が表示されていますね。